큐, 스택과 달리 중요도에 따라 먼저 처리하는 방식
- 시간에 따른 우선 순위 : 스택, 큐
-시간 외 다른 가치 우선 순위 : 우선 순위 큐
▪ 우선 순위 큐는 스택이나 큐 보다 일반적인 구조
- 키의 필요 여부
▪ <우선 순위 큐>에서는 키(= 우선 순위 값) 필드가 필요
▪ <스택>, <큐>에서는 시간에 따라 자료구조를 조직화하게 되므로 키 필드가 불필요
추상 자료형 우선 순위 큐
- 용어
▪ Create : 새로운 우선 순위 큐를 만들기
▪ Destroy : 사용되던 우선 순위 큐를 파기하기
▪ Add : 현재 우선 순위 큐에 새로운 레코드를 삽입하기
▪ Remove : 가장 우선 순위가 높은 레코드를 삭제하기
▪ IsEmpty : 현재 우선 순위 큐가 비어있는지 확인하기
- 우선 순위 큐에서의 삭제(Remove) 작업
▪ 어떤 레코드가 우선 순위가 가장 높은지는 큐 자체가 알고 있으므로 호출 함수 쪽에서는 파라미터를 넘길 필요가 없다.
우선 순위 큐의 구현
1. 배열을 이용한 구현
1) 정렬된 배열
▪ 우선 순위를 기준으로 오름차순으로 정렬
▪ 가장 우선 순위가 큰 레코드는 항상 배열의 마지막에 위치
▪ 삭제 함수는 마지막 레코드를 리턴, 배열 레코드의 개수를 하나 줄임
▪ 이 작업의 시간적 효율은 O(1)
▪ 삽입 함수는 일단 키 값을 기준으로 이진 탐색 하는데 O(lgN)
▪ 데이터 이동에 O(N)
2) 정렬 안 된 배열
▪ 새로운 레코드를 무조건 배열 끝에 붙임
▪ 삽입의 효율은 O(1)
▪ 삭제의 효율은 O(N). 처음부터 끝까지 찾아야 함
▪ 정렬된 배열과 정렬 안 된 배열을 사용할 때의 삽입, 삭제 효율은 서로 뒤바뀐 모습
▪ 삭제가 빨라야 한다면 정렬된 배열, 삽입이 빨라야 한다면 정렬 안 된 배열
▪ 삽입, 삭제 전체를 감안하면 두 방법 모두 O(N)의 효율
2. 연결 리스트를 이용한 구현
1) 우선 순위를 기준으로 내림차순으로 정렬
▪ 우선 순위가 가장 높은 레코드를 헤드 포인터가 직접 가리킴
▪ 삭제 시간은 O(1)
▪ 삽입 함수는 키 값을 기준으로 삽입 위치를 찾아야 함
▪ 최악의 경우 마지막 위치. O(N)
▪ 배열처럼 이동은 불필요
▪ 삭제와 삽입 모두를 감안한 효율은 O(1) + O(N) = O(N)

2) 정렬 안 된 연결 리스트
▪ 삽입될 레코드를 가장 첫 노드로 만들면 삽입은 O(1)
▪ 삭제를 위해 가장 큰 레코드를 찾는데 O(N)
▪ 삭제와 삽입 모두를 감안한 효율은 O(N) + O(1) = O(N)
3. 이진 탐색 트리를 이용한 구현
1) 가장 큰 키 값을 지닌 노드
▪ 루트로부터 출발해서 RChild를 계속 따라 감
▪ 더 이상 RChild가 없으므로 자식이 하나이거나 없는 노드
▪ 상대적으로 쉬운 삭제

2) 효율
▪ 삭제 함수의 효율은 O(lgN). 루트로부터 리프까지 내려감
▪ 삽입 위치를 찾아 리프 노드까지 내려가는데 O(lgN)
▪ 효율은 O(lgN) + O(lgN) = O(lgN). 단 균형 트리에 한함
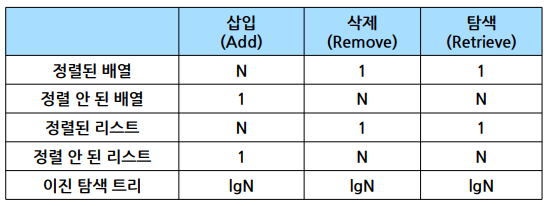
4. 구현 방법별 효율 비교
1) 자료구조별 우선 순위 큐의 효율 비교
'자료구조&알고리즘' 카테고리의 다른 글
| 재귀 호출(Recursion) (0) | 2022.03.03 |
|---|---|
| 힙(Heap)과 우선 순위 큐(Priority Queue) (0) | 2022.03.03 |
| 큐(Queue) (0) | 2022.02.24 |
| 스택의 응용 (0) | 2022.02.23 |
| 스택의 구현 (0) | 2022.02.22 |