힙를 이용한 우선 순위 큐
힙와 관련된 주요 개념 이해
1) 힙(Heap)
“쌓아 놓은 더미”
2) 용어
- 최대 힙(Max Heap)
▪ 키 값이 큰 레코드가 우선 순위가 높은 것으로 간주
▪ 루트 노드의 키가 가장 큼
- 최소 힙(Min Heap)
▪ 최대 힙과는 정반대
▪ 키 값이 작을수록 우선 순위가 높음
- 정렬
▪ 이진 탐색 트리는 값의 크기를 기준으로 삽입되기 때문에 왼쪽 노드보다 오른쪽 노드가 더 큰 값을 가짐
▪ 힙은 키를 기준으로 값을 정렬하기 때문에 값들끼리의 상관관계는 없음
힙의 특징
- 힙의 구성
힙 = "완전 이진 트리"
▪ 배열로 표시하는 것이 가장 효율적
▪ 루트부터 시작해서 위에서 아래로, 왼쪽에서 오른쪽으로 진행
▪ 노드 필기하는 순서로 트리를 순회하면서 인덱스를 부여
▪ 루트 노드는 배열 인덱스 0
- 힙은 배열로 표시
▪ 힙의 부모 자식 관계는 다음과 같은 배열의 인덱스 연산으로 바뀜

* 인덱스 K에 있는 노드의 왼쪽 자식은 (2K + 1)에, 오른쪽 자식은 (2K + 2)에 위치함
* 인덱스 K에 있는 노드의 부모 노드는 (K - 1) / 2에 위치함
힙의 삭제와 삽입
힙의 삭제
1) 우선 순위가 가장 큰 루트 노드를 삭제
▪ 루트를 직접 삭제하면 이후 힙을 재구성하는 것이 복잡
▪ 배열 마지막 요소를 루트 노드 위치에 덧씌움
2) 다운 힙(Dwon Heap)

3) 레코드의 이동
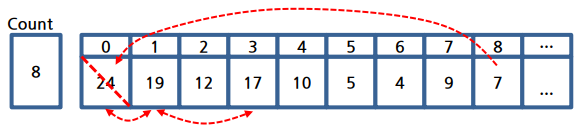
① 루트를 삭제([0] 24)
② [9] 7을 루트([0]) 자리로 이동
③ 왼쪽 자식과 오른쪽 자식을 비교해서 가장 큰 것과 교환(루트 [0] 7과 왼쪽 자식 [1] 19를 교환)

④ 교환된 [1] 7과 왼쪽 자식 [3] 17이 가장 큰 자식이므로 둘을 교환
⑤ [3] 7은 다시 왼쪽 자식 [7] 9의 키 값이 더 크므로 교환
⑥ 이렇게 하여 작은 값 7은 루트로부터 자식의 키 값이 큰 동안 계속 굴러 떨어짐
Remove (Items[ ])
{
Return Items[0]
Items[0] = Items[Count-1]
Count - -
DownHeap(Items[ ], 0)
}
[ ], Current)
{
if (Current = = Leaf)
do nothing;
else
{
Child = 2 * Current + 1
if (Currrent has RChild)
{
RChild = Child + 1
If Items[RChild] > Items[Child]
Child = RChild;
}
if (Items[Current] < Items[Child]
{
Swap Items[Current] and Items[Child]
DownHeap(Items, Child)
}
}5) 작업의 효율 : O(lgN)
▪ 배열의 마지막 레코드를 처음으로 복사하는데 O(1)
▪ 최악의 경우 루트로부터 리프까지 굴러 떨어짐
▪ 비교의 횟수는 총 2lgN이 됨
▪ 스와핑은 Temp = A, A = B, B = Temp라는 3번의 복사
▪ 최악의 경우 스와핑에 의한 복사의 횟수는 3lgN
“힙이 이진 탐색 트리보다 유리”
▪ 트리의 높이
▪ 이진 탐색 트리는 최악의 경우 연결 리스트와 유사. O(N)의 효율
▪ 힙은 완전 이진 트리로서 균형 트리
▪ 균형 트리의 높이는 항상 lg(N)에 가까움
▪ 배열로 표시되어야 하므로 최대 레코드 개수를 미리 예상해야 함
힙의 삽입과 삭제 비교
1) 삭제
“사장 자리가 비면 말단 사원을 그 자리에 앉힌 다음, 바로 아래 부하 직원보다는 능력이 좋다고 판단될 때까지 강등시키는 것”
(降等, Down Heap, Demotion)
2) 삽입
“신입사원이 오면 일단 말단 자리에 앉힌 다음, 능력껏 위로 진급시키는 것”
(進級, Up Heap, Promotion)
3) 업 힙(Up Heap)

힙의 삽입
Add (Items[ ], Data)
{
Items[Count] = Data
Current = Count;
Parent = (Current - 1) / 2
while ((Current != 0) && (Items[Current] > Items[Parent]))
{
Swap Items[Current] with Items[Parent]
Current = Parent
Parent = (Current - 1) / 2
}
Count ++
}힙의 삽입 작업 : O(lgN)
▪ 비교의 횟수
▪ 삭제에서 두 개의 자식 노드를 모두 비교. 삽입에서 자신과 부모 노드만 비교
힙을 이용한 우선 순위 큐
1. 이진 탐색 트리와 힙의 비교
1) 이진 탐색 트리와 힙

2. 힙의 정렬
- 힙을 정렬 목적으로 사용
▪ 힙에서 Remove를 가하면 키가 제일 큰 레코드가 빠져 나옴
▪ 빈 트리가 될 때까지 계속적으로 삭제를 가함
▪ 빠져 나온 레코드를 순차적으로 적어나가면 그것이 바로 정렬된 결과
▪ 내림차순: 최대 힙(Max Heap)
▪ 올림차순: 최소 힙(Min Heap)
- 가장 먼저 해야 할 것은 힙 구성(Heap Building)
▪ 주어진 레코드로부터 일단 힙을 만들어야, 빼내 오면서 정렬이 가능
▪ 하향식 힙: 탑 다운 힙(Top-down Heap)
▪ 상향식 힙: 바텀 업 힙(Bottom-up Heap)
3. 상하향식 힙의 구성
1) 하향식 힙 구성
▪ 빈 힙에서 출발하여 삽입에 의해서 힙을 구성
- 노드가 삽입될 때마다 대략 lgN의 경로를 거쳐 위로 올라감
- N개가 삽입된다면 NlgN의 효율
- 삭제 역시 하나씩 빠져 나가면서 루트로 간 레코드가 lgN 경로를 타고 내려와야 하므로 NlgN에 해당
- 정렬의 효율은 O(NlgN) + O(NlgN) = O(NlgN)
2) 하향식 힙 구성의 예시

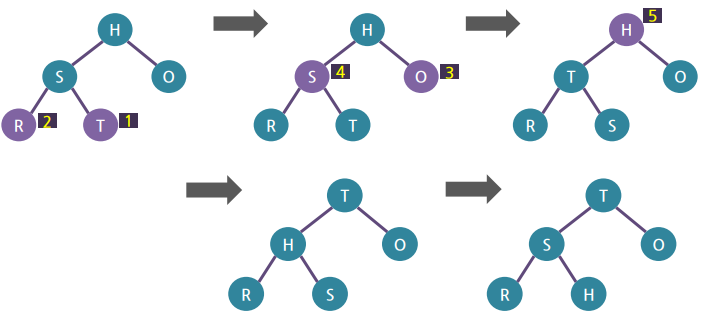
3) 상향식 힙 구성
▪ 일단 트리를 구성
- H, S, O, R, T 순으로 노트 필기하듯이 일단 트리를 구성
▪ 힙 구조가 되도록 재조정
- 가장 아래쪽부터 검사하되 오른쪽에서 왼쪽으로 진행
- 어떤 노드가 힙의 요건을 만족시키는지 검사
- 해당 노드와 그 아래쪽 노드 간의 키만 비교. 아래쪽으로만 스와핑
- 상향식 힙 구성 결과와 하향식 힙 구성 결과가 다를 수 있음
4) 상향식 힙 구성의 예시
4. 힙의 효율 비교
1) 상향식과 하향식 힙 비교
▪ 하향식 힙 구성이 O(NlgN) 상향식 힙 구성은 O(N)
▪ 삭제 단계에서는 두 방법 모두 O(NlgN). 따라서 힙 정렬은 O(NlgN)
- 쾌속 정렬은 일반적으로 O(NlgN)
- 합병 정렬이 O(NlgN)을 보장하지만 추가의 메모리가 필요
- 힙 정렬은 O(NlgN)을 보장하면서 추가의 메모리가 불필요
- 그러나 내부 루프 처리시간이 쾌속 정렬보다 길기 때문에 일반적으로는 쾌속 정렬보다는 느림
'자료구조&알고리즘' 카테고리의 다른 글
| 재귀 함수(Recursive Function) (0) | 2022.03.04 |
|---|---|
| 재귀 호출(Recursion) (0) | 2022.03.03 |
| 우선순위 큐 (0) | 2022.02.25 |
| 큐(Queue) (0) | 2022.02.24 |
| 스택의 응용 (0) | 2022.02.23 |